
A quick recap of the basic terminology of Kafka can be found here.
The fundamental unit that Kafka manages is called a message. Message is simply a byte array without any restriction of the format. As you would know, producers produce data to a topic. Each topic is further divided into multiple partitions. Messages are sent from producer to Kafka in batches. A batch is a collection of messages that are produced to a particular topic and partition. This batching is done in order to avoid the round trip across the network for each individual message.
But why is the data in a topic stored in multiple partitions?
Imagine partition as a file. Each message is appended at the end of the file. Messages are read from the start to the end of the file. Partitions can be distributed across the brokers. Since messages are produced to different partitions of a topic, one can not expect the guarantee of time ordering across all messages. However, messages in one partition have a guarantee of time ordering.
Partitions are the way Kaka ensures scalability and redundancy. Each partition can be hosted on a different server, which means that a single topic can be scaled horizontally across multiple servers to provide performance far beyond the ability of a single server. This effectively means that when the count of messages are low, you can have your all partitions on one broker. On the other hand, if the message count and size increases, we can have just one partition on one server. One particular partition cannot be split between multiple brokers and not even between multiple disks on the same broker. Therefore, size of a partition is limited by the space available on a single mount point.
Replication is the core of Kafka. Each partition is replicated for redundancy and for the inevitable failure of hardware.
How does Kafka handle replication?
There are two types of replica: Leader replica and Follower replica. Let’s say there are three replicas of a partition. One of them, should be a leader. All the requests from producers and consumers would pass to the leader in order to guarantee consistency. All the replicas other than the leader are called follower. Follower do not serve any request and their only task is to keep themselves updated with the leader. One of the follower replicas become the leader in case the leader fails.
How does a follower stay in sync with the leader?
Follower sends a FETCH request to the leader. The request has the offset of the message that Kafka wants to receive next and will always be in the order. A replica will request message 1, then message 2, and then message 3, and it will not request message 4 before it gets the message 1, 2 and 3. Therefore the leader knows that a replica got all messages up to message 3 when the replica requests message 4. Leader knows how far behind each replica is by looking at the last offset requested by each replica. A replica is considered out of sync if the replica hasn’t requested a message in more than ten seconds. Any out of sync replica can not become leader.
What protocol does Kafka use for communication? Is it HTTP?
Kakfa does not uses HTTP. Kafka uses a binary protocol over TCP. The protocol defines all APIs as request and response message pairs. The client initiates a socket connection and then writes a sequence of request messages and reads back the corresponding response message. The client will likely need to maintain a connection to multiple brokers, as data is partitioned and the clients will need to talk to the server that has their data.
The server guarantees that on a single TCP connection, requests will be processed in the order they are sent and responses will return in that order as well. The broker’s request processing allows only a single in-flight request per connection in order to guarantee this ordering. Note that clients can (and ideally should) use non-blocking IO to implement request pipelining and achieve higher throughput. i.e., clients can send requests even while awaiting responses for preceding requests since the outstanding requests will be buffered in the underlying OS socket buffer. All requests are initiated by the client, and result in a corresponding response message from the server.
The server has a configurable maximum limit on request size and any request that exceeds this limit will result in the socket being disconnected.
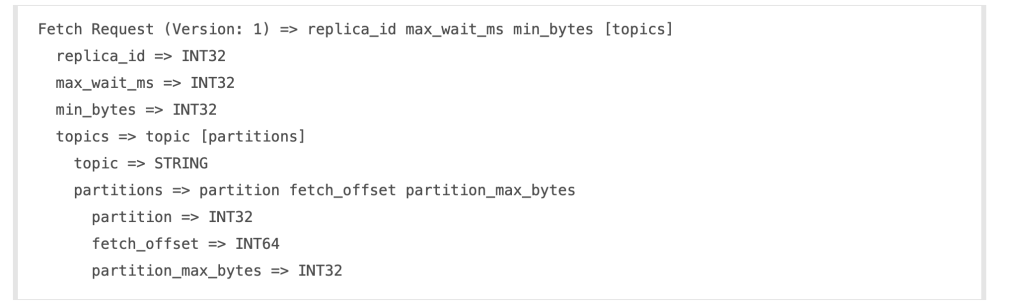
What do Kafka developers have to say about their choice of communication protocol?

Physical Storage
Let’s assume that we have the following scenario:
Number of broker: 3
One topic with 9 partition and replication factor of 2. That means, we have a total of 18 partitions.
Now, Kafka would try to assign 6 partition (18/3) on each broker so that no two replica are on same broker. If the rake information is available, it is also considered in the allocation of partition to a broker.
How does Kafka retain a message for the specified duration?
Each topic has a specified retention period or the size after which the messages are deleted, even if all the consumers have not read the message. Kafka splits each partition into segments. Each segment contains either 1 GB of data or a week of data, whichever is smaller, by default. As a Kafka broker is writing to a partition, if the segment limit is reached, we close the file and start a new one. The segment we are currently writing to is called an active segment. The active segment is never deleted, so if you set log retention to only store a day of data but each segment contains five days of data, you will really keep data for five days because we
can’t delete the data before the segment is closed. If you choose to store data for a week and roll a new segment every day, you will see that every day we will roll a new segment while deleting the oldest segment, so most of the time the partition will
have seven segments.
What is the file format of each segment?
Each segment is stored in a single data file. Inside the file, we store Kafka messages and their offsets. The format of the data on the disk is identical to the format of the messages that we send from the producer to the broker and later from the broker to the consumers. Using the same message format on disk and over the wire is what allows Kafka to use zero-copy optimization when sending messages to consumers and also avoid decompressing and recompressing messages that the producer already
compressed. Each message contains—in addition to its key, value, and offset—things like the message size, checksum code that allows us to detect corruption, magic byte that indicates the version of the message format, compression codec (Snappy, GZip, or LZ4), and a timestamp.
What are indexes in Kafka?
Kafka allows consumers to start fetching messages from any available offset. This means that if a consumer asks for 1 MB messages starting at offset 100, the broker must be able to quickly locate the message for offset 100 (which can be in any of the
segments for the partition) and start reading the messages from that offset on. In order to help brokers quickly locate the message for a given offset, Kafka maintains an index for each partition. The index maps offsets to segment files and positions within the file.
What is compaction in Kafka?
Kafka allows the retention policy on a topic to compact, which only stores the most recent value for each key in the topic. Obviously, setting the policy to compact only makes sense on topics for which applications produce events that contain both a key and a value. If the topic contains null keys, compaction will fail.
Set up your first producer and consumer by following the tutorial here.
Reference
If you liked this article and would like one such blog to land in your inbox every week, consider subscribing to our newsletter: https://skillcaptain.substack.com
