
What is a data stream or event stream?
A data stream is an abstraction representing an unbounded dataset. Unbounded that data is infinite and it grows over time as the new record keep getting added to the dataset. The data contained in the events or the number of events per second. The data differs from system to system—events can be tiny (sometimes only a few bytes) or very large (XML messages with many headers); they can also be completely unstructured, key-value pairs, semi-structured JSON, or structured Avro or Protobuf messages.
What are the example of data stream?
Every business transaction can be seen as stream of events. Think about the case when you do a payment through your favourite mobile wallet app. We can summarise the business transaction as following set of events:
- Open the app.
- Authenticate through your biometric details or enter the pass code.
- Scan the QR code or the wallet Id of the receiver.
- Enter the amount to be transferred.
- Enter the secure code.
- Get the payment confirmation screen.
Just like this, every other business transaction too can be modelled as the sequence of the events. Think of stock trades, package deliveries, network events going through a switch, events reported by sensors in manufacturing equipment, emails sent, moves in a
game – all of this is essentially stream of events.
What are the properties of data stream?
- Event streams are ordered – Events are ordered with respect to the time. We can say with confidence that the event X has occurred after the event Y. The business transaction where first event is 1000$ credit and second event is 1000$ debit to a bank account is different from the business transaction where debit occurs first and the credit happens next. The second business transaction involves overdraft charges where as the first business transaction is fairly normal one.
- Immutable data records – Events can never be modified after it has occurred. A cancelled financial transaction does not disappear. Rather, we have another event that does the cancellation against the previous transaction.
- Event streams are replayable – This is a desirable property. It is critical to be able to replay a raw stream of events that occurred months (and sometimes years) earlier for the majority of the business applications. This is required in order to correct errors, try new methods of analysis, or perform audits.
Stream-Processing
Stream processing fills the gap between the request-response world where we wait for events that take two milliseconds to process and the batch processing world where data is processed once a day and takes many hours to complete. Many business processes does not need either request response or batch processing. They may want something that continuously reads data from an unbounded dataset, doing something to it, and emitting output, which can be then presented as a report to the end user or stored in database as some business property. The processing has to be continuous and ongoing.
Stream-Processing Concepts
Stream processing is just like any other data processing where:
a. Get the data.
b. Do transformation on data.
c. Aggregate the data.
d. Store the data.
e. Present the data.
However, there are some key concepts which are useful for developing any stream application.
Time
In the context of stream processing, having a common notion of time is critical because most stream applications perform operations on time windows. For example, our stream application might calculate a moving five-minute count of total order placed. In that case, we need to know what to do when one of our data servers goes offline for two hours due to any issues and returns with two hours worth of data—most of the data will be relevant for five-minute time windows that have long passed and for which the result was already calculated and stored.
Stream processing frameworks have following sense of time:
Event time
This is the time when the event happened. For example, when any user visits our website, that time is the event time for that event. Event time is usually the time that matters most when processing stream data.
Processing time
This is the time at which a stream-processing application received the event in order to perform some calculation. This time can be milliseconds, hours, or days after the event occurred. This notion of time is highly unreliable and best avoided.
State
Stream processing for a single event may be easy. But stream processing usually are more evolved than that. Stream processing usually contains following (but not limited to) operations:
- Counting the number of events by type
- Moving averages over 5 minutes window
- Joining two streams to create an enriched stream of information
- Aggregating data over hour
- Sum, average, quantile over data
We call the information that is stored between events a state. State can be of following two kinds:
Internal State
State that is accessible only by a specific instance of the stream-processing application. This state is usually maintained and managed with an embedded, memory database running within the application. Embedded memory database allows it to be very fast. However, since it’s in-memory, we are limited by the amount of the data that it can store. As a consequence, sometimes stream processing is done by making several sub-stream of the data so that processing can be done using internal state.
External State
State that stores data in any external datastore like Cassandra are called external state. The advantage of this state is that we have unlimited memory and the data is accessible from anywhere. However, being external mean that we would have to bear external latency and added complexity of external system.
Stream-Table Duality
A database table allows checking the state of the data at a specific point in time. Unlike tables, streams contain a history of changes. Streams are a string of events wherein each event caused a change. A table contains a current state of the world, which is the result of many changes.
Let’s assume that we are tracking event of an ATM machine. Following events could happen:
- Bank stores 10000$ in the ATM at 10:00 AM.
- Person A withdraws 10K at 10:05 AM.
- Person B withdraws 1K at 11:05 AM.
- Person C withdraws 2K at 12:05 PM.
- Person D withdraws 3K at 12:08 PM.
- Person E withdraws 4K at 03:05 PM.
The database would tell us that at any point of time, what is the balance in the ATM. Stream would tell us how busy is that ATM. Which is the busiest hour? Stream and database are the two views to represent a business transaction.
Stream Processing Design Pattern
Single-Event Processing
Here, stream processing framework consumes a single message and do some data manipulation and then writes the output to any other stream. An example could be, a framework that checks fraud_probablity of each event and puts it into a stream that sends email to the end user.
Processing with Local State
Most stream-processing applications are concerned with aggregating information, especially time-window aggregation. An example could be to find the busiest hour of the website in order to scale the infrastructure. These aggregations require maintaining a state for the stream. As in our example, in order to calculate the number of website hits in an hour, we need to keep a counter to keep track of website hits in moving window of one hour. This could be done in a local state.
Assume we want to find hits on different pages of website, we can partition the streams based on different pages and then aggregate it using a local state.
However, local state should be accommodated in the memory and it should be persisted so that if the infrastructure crashes, we are able to recover the state.
Multiphase Processing
The multiphase processing incorporates following phases:
- Aggregate data using a local state
- Publish the data into a new stream
- Aggregate the data using the new stream mentioned in phase 2.
This type of multiphase processing is very familiar to those who write map-reduce code, where you often have to resort to multiple reduce phases.
Stream-Table Join
Sometimes stream processing requires integration with data external to the stream— validating transactions against a set of rules stored in a database, or enriching clickstream information with data about the users who clicked.
Now, making an external database call would mean not only extra latency, but also additional load on the database. The other constraint is that for the same sort of infrastructure, amount of events that can be processed by streaming platform is order of magnitude higher than what a database would process. So, this is clearly not a very scalable solution. Caching can be one strategy, but then caching the data means one need to manage cache infrastructure and manage data lifecycle. For example – how would you make sure that the data is not stale. One solution could be to ensure that the database changes are streamed and cache is updated based on the data in the stream.
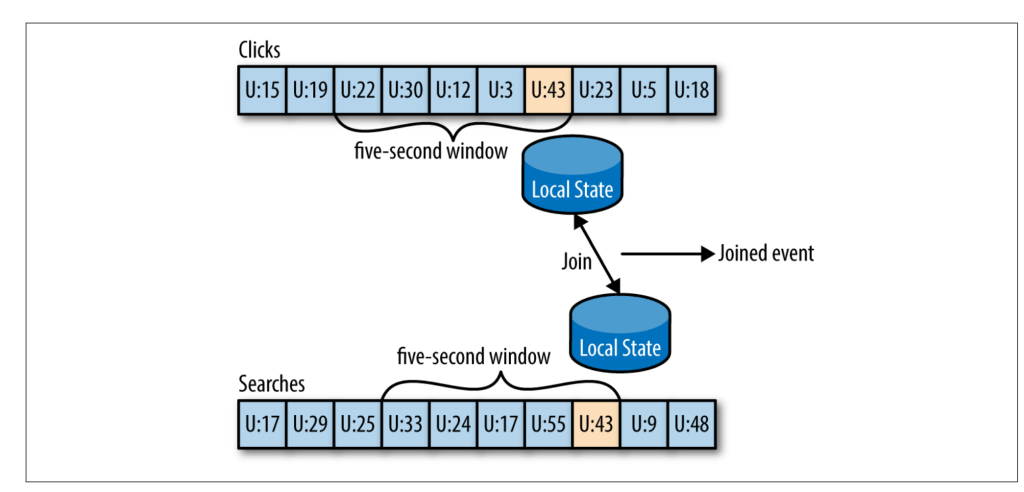
Streaming Join
For example, let’s say that we have one stream with search queries that people entered into our website and another stream with clicks, which include clicks on search results. We want to match search queries with the results they clicked on so that we will know which result is most popular for which query. When you join two streams, you are joining the entire history, trying to match events in one stream with events in the other stream that have the same key and happened in the same time-windows. This is why a streaming-join is also called a windowed-join.
Out-of-Sequence Events
Handling events that arrive at the stream at the wrong time is a challenge not just in stream processing but also in traditional ETL systems. For example, a mobile device of a Uber driver loses mobile signal for a few minutes and sends a few minutes worth of events when it reconnects.

In such scenario, the framework has to do following things:
a. Recognize that an event is out of sequence.
b. Define a time period during which it will attempt to reconcile. Outside the prescribed time period, the data will be considered useless.
c. Be able to update results which might mean updating a row in database.
Common Stream Processing Frameworks
Apache Storm, Apache Spark Streaming, Apache Flink, Apache Samza.
Kafka also provides with streaming APIs.
Reference:
Kafka – The Definitive Guide
If you liked this article and would like one such blog to land in your inbox every week, consider subscribing to our newsletter: https://skillcaptain.substack.com

Leave a Reply