Introduction
Assume that we have been given following mockup screens:

A possible rest implementation would have following APIs:
GET /car/{id}
Response:
{
"id" : "car1",
"carNumber" : "KA01HK",
"driverId" : "12"
}
-------------------------------------
GET /driver/{id}
Response:
{
"id" : "12",
"firstName" : "Harsh",
"lastName" : "Vardhan"
}But!
The first screen only wanted car number on the basis of car id. Why are we sending driverId too. Perhaps this example is too simple to make worth of the extra unnecessary information that we are sending. But imagine the actual production database table of car; it will have colour, data of manufacture, kilometres travelled, chassis number, fuel type and the list goes on.
That’s not the biggest problem on earth. We can any day do something like below to get rid of unwanted information.
GET /car/{id}?include=carNumber
Response:
{
"id" : "car1",
"carNumber" : "KA01HK"
}
But that would mean writing as many API signature as number of use cases and more maintenance headache for backend engineers . Also, that means our API is non intuitive. This also increases the stress on documentation. Add to it, more coordination needed between backend and frontend developers.
With this premise, I would like to introduce GraphQL.
GraphQL
Though not exactly, we can take the liberty of saying, GraphQL is to be used instead of REST architecture.
GraphQL is:
- query language for the API
- specification
- collection of tools
- designed to operate over single endpoint over HTTP
- optimised for performance
- optimised for flexibility
- server-side runtime for executing queries by using a type system we define for our data
- isn’t tied to any specific database or storage engine
- is backed by our existing code and data
For the sake of the tutorial, we will try to show graphQL running for the same mock ups and introduce some concepts on the way. You may download the sample demo project from here and run it as normal java project.
Endpoint
GraphQL is designed to operate on single endpoint over HTTP. Our API is as below:
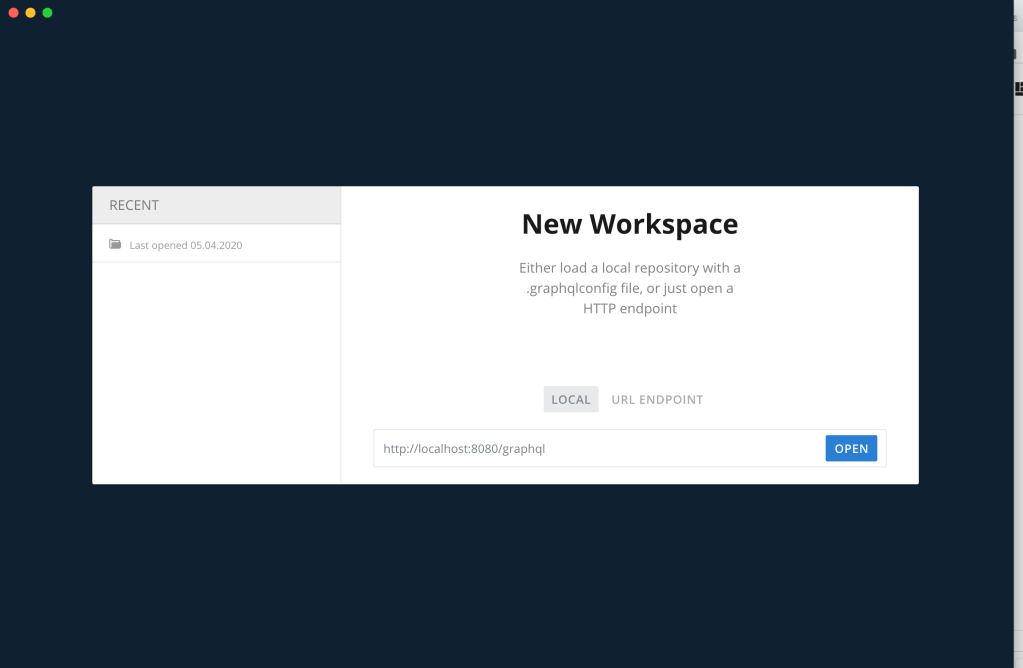
http://localhost:8080/graphqlWe will run it in the GraphQL playground.
Open the graphQL playground and enter the above mentioned link in the URL; select the URL Endpoint above the text box and click open.
Query
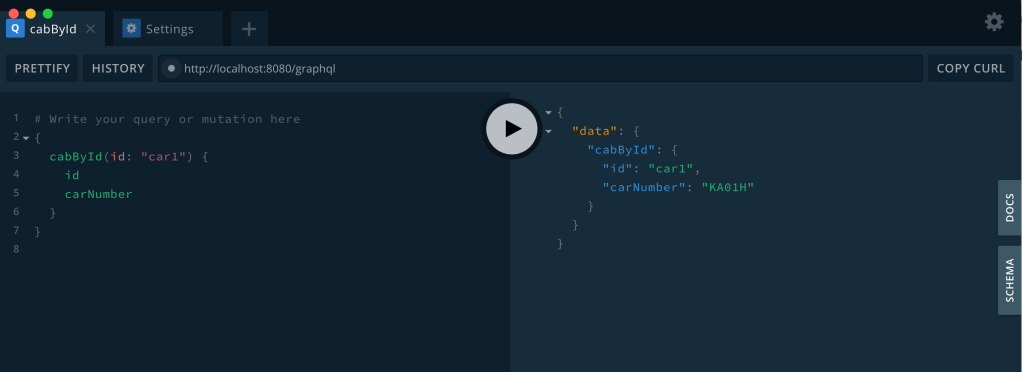
For the first screen in the mock up, we need car number based on the car Id. A simple query like the one shown below will be sufficient for the first screen. At this point, do not worry about how did that string “cabById” came into picture. And also do not worry about weird JSON like syntax. We will learn more about it as we go forward.
{
cabById(id: "car1") {
id
carNumber
}
}
But what if, we want to also have driverId in the response. Simple, just add driver object and ask for id in the query.
{
cabById(id: "car1") {
id
carNumber
driver{
id
}
}
}
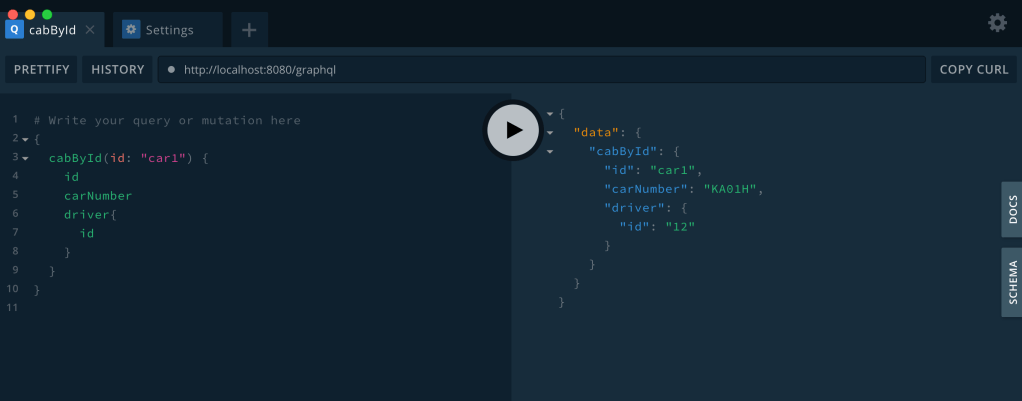
The point which I am trying to make here is that the endpoint did not change. GraphQL is client driven. It enables clients to ask for exactly what they need and nothing more. It makes it easier to evolve APIs over time.
Now, that we know how does a query runs, let’s see the structure of the query. GraphQL asks for specific fields on objects. Here, in our first query, we are asking for id and car number on the car object that is queried by using it’s id – “car1”. The entity “carNumber” and “id” is known as fields in GraphQL language. The noticeable feature of query and response is that query and result have exactly the same shape. And this is what GraphQL guarantees; you always get back what you expect. The string (“id: “car1”) is called argument in GraphQL language.
Implement a GraphQL Server in Java
If you have stayed with me till now, hopefully you will be answer to the following introductory questions.
- What is GraphQL?
- How it is different from REST?
- How the client uses GraphQL?
- What is the basic structure of GraphQL?
The next part we will focus on building a GraphQL server. The same one from github which I was using it as example so far and hopefully you must have run it.
We are going to use spring. So, make a java maven project and use the following pom.xml.
Schema
Create a new file schema.graphqls in src/main/resources with the following content:
type Query {
cabById(id: ID): Cab
}
type Cab {
id: ID
carNumber: String
driver: Driver
}
type Driver {
id: ID
firstName: String
lastName: String
}It has a top level field called cabById and other fields are self explanatory.
pom.xml
Please use your own group Id, artifact id or anyother project specific details.
Main File
The class with main method looks like the one in gist below. This is a simple Spring Boot Application main method.
Data Fetchers
A Data Fetcher fetches the data for one field while the query is executed. When GraphQL Java is executing a query, it calls appropriate Data Fetcher for each field it encounters in the query. In another words, Every field from the schema has a DataFetcher. If there is not any defined data fetcher for any specific field, then the default PropertyDataFetcher is used. PropertyDataFetcher is the name of field in case of java class or key in case of Map. DataFetcher interface is defined as follow in the GraphQL java code.
Data Fetcher class for our project is shown in the gist below.
public interface DataFetcher<T> {
T get(DataFetchingEnvironment dataFetchingEnvironment) throws Exception;
}Our first method getCabByIdDataFetcher returns a DataFetcher implementation which takes a DataFetcherEnvironment and returns a car. We need to get the id argument from the cabById field in the query. We find the car that has the same id as asked in the query and return it.
Our second method getDriverDataFetcher is similar to the first one except for the fact that the carInStore object from first method is made available to it using the getSource method.
Glue in Data Fetcher and Schema
This GraphQLProvider class has a “init” method that brings everything together and serves as GraphQL server. It parses the schema and attaches appropriate DataFetcher to each field. We will come to this classes again in subsequent post to discuss at length.
Run the code as you would normally run a java code.
At this point your graphQL server would be running. While this post tries to give a brief introduction about graphQL in general and how to use it, this is no way comprehensive and I hope to cover more later.
As always, feel free to drop in suggestion and comments.
Download the project
https://github.com/rohitsingh20122992/cab-details-graphQL-demo
Update
Read second part of this series here.
References:
https://phil.tech/api/2017/01/24/graphql-vs-rest-overview/
https://www.graphql-java.com/tutorials/getting-started-with-spring-boot/
https://blog.apollographql.com/the-anatomy-of-a-graphql-query-6dffa9e9e747
https://www.toptal.com/api-development/graphql-vs-rest-tutorial
If you liked this article and would like one such blog to land in your inbox every week, consider subscribing to our newsletter: https://skillcaptain.substack.com
